About Me
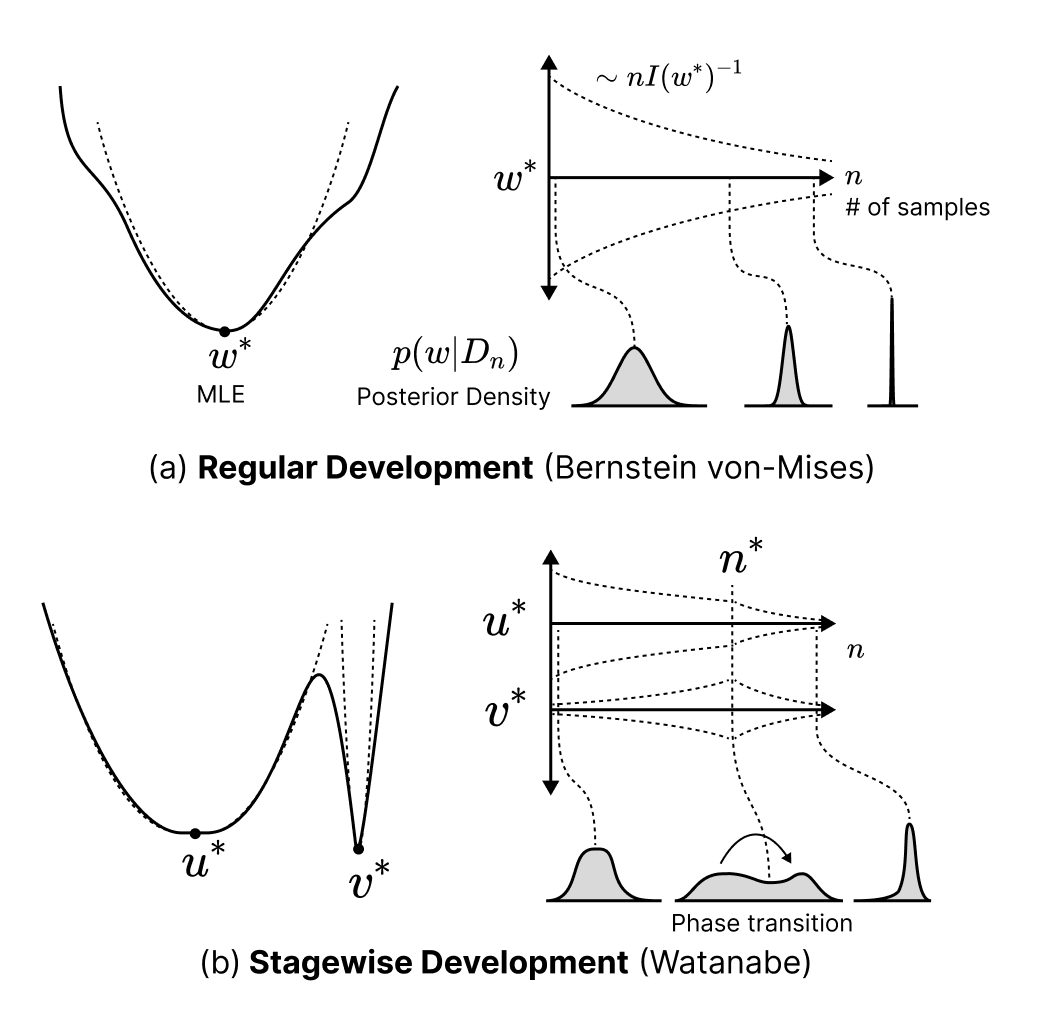
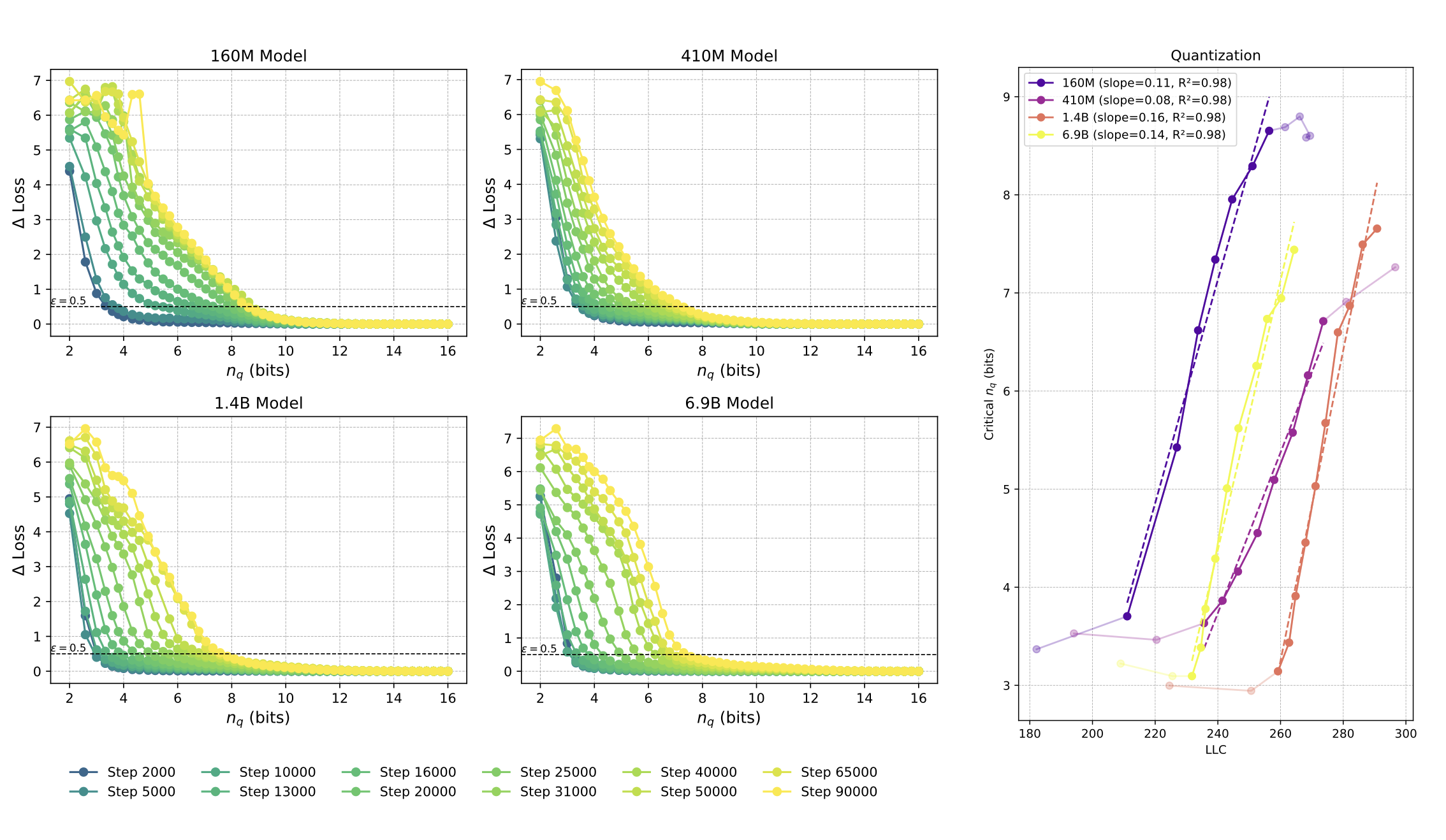
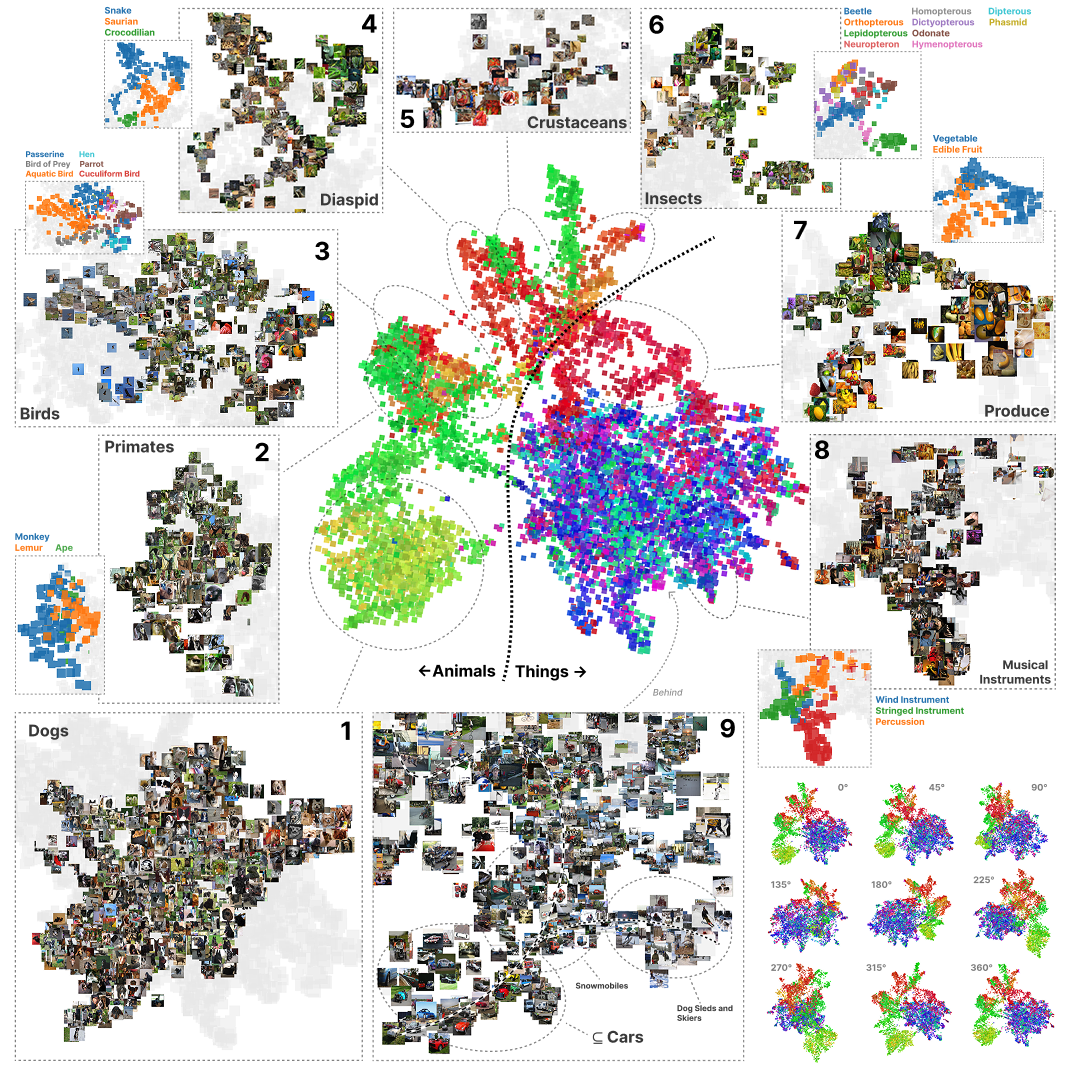
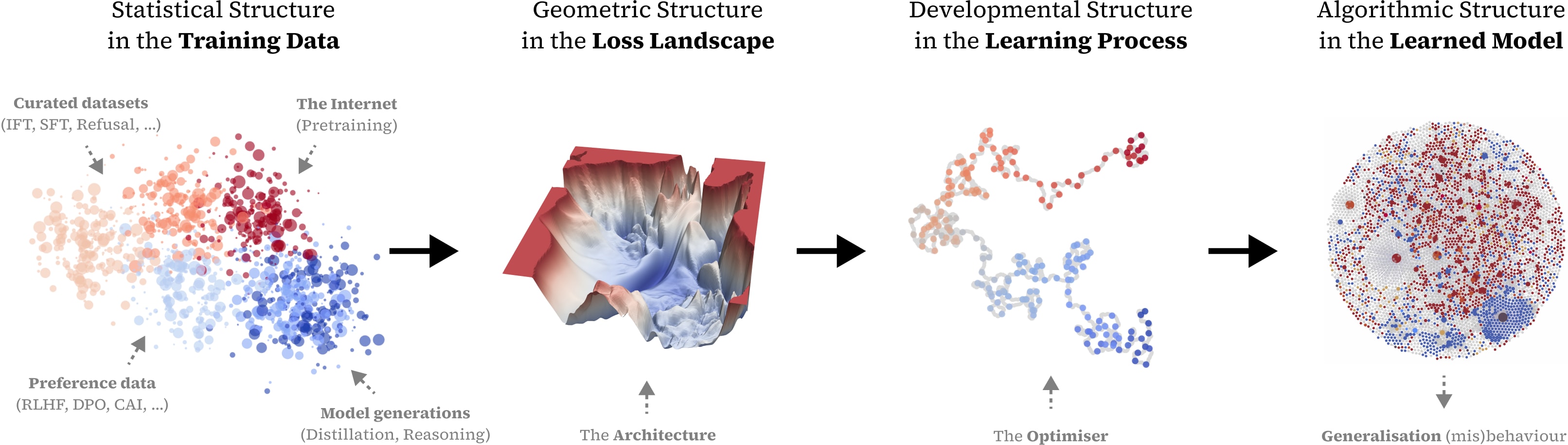
Hi, I'm Jesse. I'm co-founder and executive director of Timaeus, an AI safety research org working on applications of Singular Learning Theory (SLT) for AI safety. SLT establishes a connection between the geometry of the loss landscape and internal structure in models, which we are using to develop scalable, rigorous tools for evaluating, interpreting, and aligning neural networks.
Website • GitHub • LessWrong • Twitter • LinkedIn • Email me