Generalization
NOTE: Work in Progress
Outline
- Warm-up: MSE & bias-variance trade-offs.
- Generalization = Simplicity.
- Solomonoff induction,
- Complexity measures
- BIC/MDL, AIC
- VC dimension & structural risk minimization
- Rademacher complexity
- Early Stopping
- NTK
- Problems:
- Vacuous bounds (Zhang et al. 2017). Always zero training error. Any optimizer (even stupid ones). Crazily convex loss spots. Even with regularization
- From functions to probabilities
- Gibbs measure
- PAC-Bayes bounds
- Singular learning theory, WAIC
- Mingard-style “Bayesian inference”
Misc:
- SGD & Basin broadness
- Heavy-tailed random matrix theory (implicit self-regularization)
- Double descent & grokking
- Recent Anthropic work It’s non-obvious that (l2) regularization chooses simpler functions in NNs. (Polynomial regression is one thing).
"Regular" learning theory (RLT) predicts that overparametrized deep neural networks (DNNs) should overfit. In practice, the opposite happens: deeper networks perform better and generalize further. What's going on?
The consensus is still out, but different strands of research appear to be converging on a common answer: DNNs don't overfit because they're not actually overparametrized; SGD and NN's symmetries favor "simpler" models whose effective parameter counts are much lower than the externally observed parameter count. Generality comes from a kind of internal model selection where neural networks throw out unnecessary expressivity.
In this post, I'll make that statement more precise. We'll start by reviewing what RLT has to say about generalization and why it fails to explain generalization in DNNs. We'll close with a survey of more recent attempts at the learning theory of DNNs with particular emphasis on "singular" learning theory (SLT).
Intro to Statistical Learning Theory
Before we proceed, we need to establish a few definitions. Statistical learning theory is often sloppy with its notation and assumptions, so we have to start at the basics.
In this post, we'll focus on a (self-)supervised learning task. Given an input , we'd like to predict the corresponding output . This relationship is determined by an unknown "true" pdf over the joint sample space .
If we're feeling ambitious, we might directly approximate the true joint distribution with a generative model that is parametrized by weights . If it's tractable, we can marginalize this joint distribution to obtain the marginal and conditional distributions. 1
If we're feeling less ambitious, we might go ahead with a discriminative model of the conditional distribution, . (In the case of regression and classification, we're interested in inferring target values and labels from future samples, so we may not care all that much about and .)
And if we're feeling unambitious (as most machine learning theorists are), it may be enough to do direct inference with a discriminant function — i.e., to find a deterministic function that maps inputs to outputs, .2
In the case of regression, this is justified on the (only occasionally reasonable) assumption that the error is i.i.d. sampled from a Gaussian distribution. In other words, the discriminative model is defined in terms of as:
Machine learning usually begins with discriminant functions. Not only is this often easier to implement, but it offers some additional flexibility in the kinds of functions we can model because we optimize arbitrary loss functions that are unmoored from Bayesian-grounded likelihoods or posteriors.3
This flexibility comes at a cost: without the theoretical backing, it's more difficult to reason systematically about what's actually going on. The loss functions and regularizers of machine learning often end up feeling ad hoc and unsupported because they are. Or at least they will be until section 3.
As a result, we'll find it most useful to work at the intermediate level of analysis, in terms of discriminant models.
What Is Learning, Anyway?
The strength of the Bayesian framing is that for some prior over weights, , and a dataset of samples , we can "reverse" the likelihood (assuming each sample is sampled i.i.d. from ),
to obtain the a posteriori distribution,
where is the evidence (or partition function),
The aim of "learning" is to make our model as "close" as possible to the truth .
In the probabilistic formulation, the natural choice of "distance" is the Kullback-Leibler divergence (which is not actually a distance):
where the second equality follows from defining .
Formally, the aim of learning is to solve the following:
We say is realizable iff , in which case we call the "true" parameters.
At this point, we run into a bit of a problem: we can't actually compute the expectations since we don't know (and even if we did, the integration would likely be intractable). Instead, we have to resort to empirical averages over a dataset,. 3
Maximum Likelihood Estimation is KL-Divergence Minimization
Example: Regression & Mean-Squared Error
Fortunately, there's a more general and principled way to recover discriminant models from discriminant functions than the assumption of isotropic noise, as long as we're willing to relax Bayes' rule.
First, we introduces a parameter that controls the tradeoff between prior and likelihood to obtain the tempered Bayes update [1],4
where is a dataset of samples , and the likelihood is obtained by assuming each sample is distributed i.i.d. according to s.t. .
Next, we replace the tempered likelihood with a general loss function
The real-world is noisy, and pure function approximation can't account for this.
To remedy this, it's common to model any departure from our deterministic predictions, , as isotropic noise, e.g., .
Physically, we may expect the underlying process to be deterministic (given by a "true" function ) with noise creeping in through some unbiased measurement error .
For Gaussian noise, the NLL works out to:
Assuming isotropic Gaussian noise in a regression setting, we see that MLE simplifies to minimizing the mean squared error (up to some overall constant and scaling).
To make MLE more Bayesian, you just multiply the likelihood by some prior over the weights, to obtain maximum a posteriori estimation (MAP): If we enforce a gaussian prior with precision , the loss gains a regularization term (weight decay), to the loss function. [2]
Gibbs Generalization Error
Todo
What Is Generalization, Anyway?
Consider the empirical probability distribution,
where is a delta function appropriate to the sample space.
Although this will converge to the true distribution as , for any finite , we encounter sampling error. This problem is particularly pronounced for unseen samples: may (and almost always does) assign zero probability to samples that have non-zero probability under the true distribution.
The fundamental challenge of generalization is to make predictions about these unseen samples. Let's make this more precise.
Given some loss function , we're interested in how performs on future samples, as measured by the expected risk or generalization error,
However, we can only estimate this performance on on the available dataset via the empirical risk,
where denotes an empirical average over the dataset, .
Our problem is that the true generalization error is unknowable. So, in practice, we split our dataset into a training set, , and test set, , respectively. We learn our parameters via the training set, and then estimate the generalization error on the test set. That's where we encounter our first major confusion.3
You see, besides the generalization error, there's the distinct notion of the generalization gap,
Whereas generalization error is about absolute performance on the true distribution, the generalization gap is about relative performance between the training and test sets. Generalization error combines both "performance" and "transferability" into one number, while the generalization gap is more independent of "performance" — past a certain threshold, any amount of test-set performance is compatible with both a low and high generalization gap.
For the remainder of this post, I'll focus on the generalization gap. It's not absolute performance we're interested in: universal approximation theorems tell us that we should expect excellent training performance for neural networks. The less obvious claim is why this performance should transfer so well to novel samples.
Yes, more data means better generalization, but that's not what we're talking about.
In the limit , the empirical risk converges to expected risk, and both generalization error and gap will fade away: So obviously the larger datasets that have accompanied the deep learning boom explain some of the improvement in generalization.
PAC Learning
Established by Valiant (1984) [3], Probably Approximately Correct (PAC) learning establishes upper bounds for the risk . In its simplest form, it states that, for any choice of ("probably") a predictor, , will have its risk bounded by some ("approximately correct"):
Originally, PAC learning included the additional assumption that the predictor was polynomial in and , but this has been relaxed to refer to any bound holding with high probability.
Still, it's not a full explanation as typical networks can easily memorize the entire training set (even under random labelings [4]).
MSE & Bias-variance tradeoff
In the case of isotropic noise (where our loss function is the MSE), the generalization error of a model is:
In other words, it is the (l2) distance between our predictions and the truth averaged over the true variables . The bias-variance decomposition splits the generalization error into a bias term,
which measures the average difference between predictions and true values, a variance term,
which measures the spread of a model's predictions for a given point in the input space, and an irreducible error due to the inherent noise in the data. (For Gaussian noise, the irreducible error is .)
In order to achieve good generalization performance, a model must have low bias and low variance. This means that the model must be complex enough to capture the underlying patterns in the data, but not so complex that it overfits the data and becomes sensitive to noise. In practice, these two forces are at odds, hence "tradeoff."
Generalization is about simplicity
A common assumption across the entire statistical learning theory literature is that of simple functions generalizing better. It's worth spending a second to understand why we should expect this assumption to hold.
Occam's Razor
"Entities must not be multiplied beyond necessity".
Occam's razor is the principle of using the simplest explanation that fits the available data. If you're reading this, you probably already take it for granted.
Solomonoff Induction
Algorithmic complexity theory lets us define a probability distribution over computable numbers,
where is the (prefix) Kolmogorov complexity. The probability of any given number is the probability that a uniform random input tape on some Universal Turing Machine outputs that number. Unfortunately, the halting problem makes this just a tad uncomputable. Still, in principle, this allows a hypercomputer to reason from the ground up what the next entry in a given sequence of numbers should be.
Bayesian/Akaike Information Criterion
One of the main strengths of the Bayesian frame is that it lets enforce a prior over the weights, which you can integrate out to derive a parameter-free model:
One of the main weaknesses is that this integral is often almost always intractable. So Bayesians make a concession to the frequentists with a much more tractable Laplace approximation (i.e., you approximate your model as quadratic/gaussian in the vicinity of the maximum likelihood estimator (MLE), ):
where is the Fisher information matrix:
From this approximation, a bit more math gives us the Bayesian information criterion (BIC):
The BIC (like the related Akaike information criterion) is a criterion for model selection that penalizes complexity. Given two models, the one with the lower BIC tends to overfit less (/"generalize better").
That is, simpler models (with fewer parameters) are more likely in approximate Bayesian inference. We'll see in the section on singular learning theory that the BIC is unsuitable for deep neural networks, but a generalized version, the Widely Applicable Bayesian Information Criterion (WBIC) will pick up the slack.
Minimum Description Length
The BIC is formally equivalent to MDL. TODO
Maximum Entropy Modeling
TODO
Classic Learning Theory
As we've seen in the previous section, the question of how to generalize reduces to the question of how to find simple models that match the data.
In classical learning theory, the answer to this is easy: use fewer parameters, include a regularization term, and enforce early stopping. Unfortunately, none of these straightforwardly help us out with deep neural networks.
For one, double descent tells us that the relation between parameter count and generalization is non-monotonic: past a certain number of parameters, generalization error will start decreasing. Moreover, a large number of the complexity measures we've seen are extensive (they scale with model size). That suggests they're not suited to the task.
As for regularization, it gets more complicated. That regularization on polynomial regression leads to simpler functions is straightforward. That regularization on deep neural networks leads to simpler models is less obvious. Sure, a sparse l1 regularizer that pushes weights to zero seems like it would select for simpler models. But a non-sparse l2 regularizer? Linking small parameters to simple functions will require more work. A deeper problem is that DNNs can memorize randomly labeled data even with regularizers [5]. Why then, do DNNs behave so differently on correctly labeled (/well-structured) data
Other forms of regularization like dropout are more understandable: they explicitly select for redundancy which collapses the effect parameter count.
Finally, early stopping doesn't seem to work with the observation of grokking: in certain models, training loss and test loss may plateau (at a poor generalization gap) for many epochs before training loss suddenly sharply decreasing (towards a much better generalization gap).
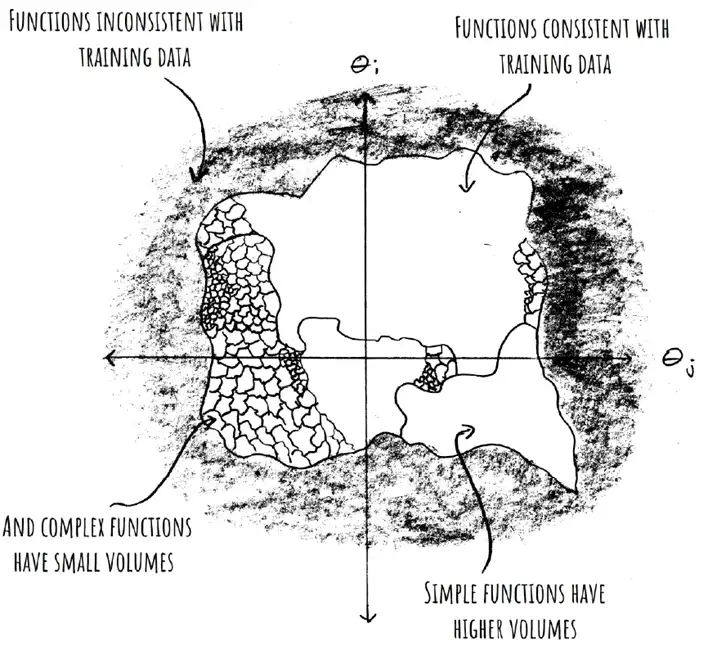
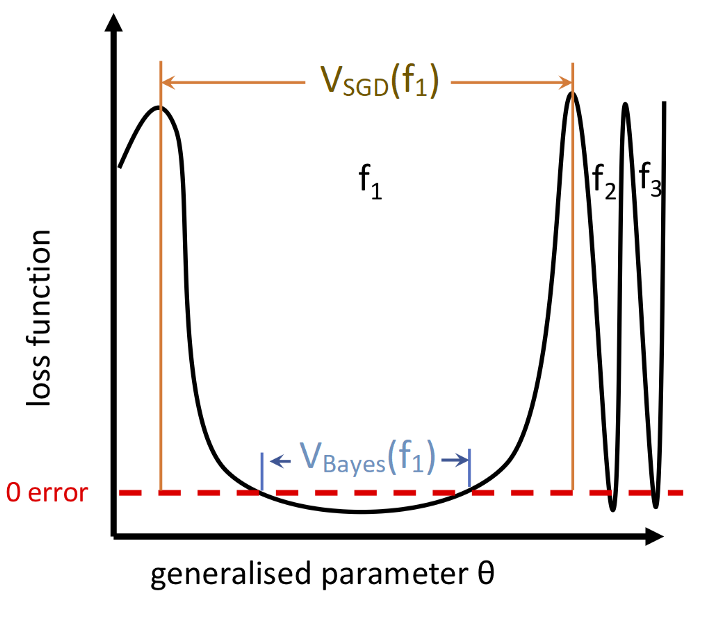
SGD Favors Flat Minima
- is the probability that expresses on upon a randomly sampled parametrization. This is our "prior"; it's what our network expresses on initialization.
- is a volume with Gaussian measure that equals under Gaussian sampling of network parameters.
- This is a bit confusing. We're not talking about a continuous region of parameter space, but a bunch of variously distributed points and lower-dimensional manifolds. Mingard never explicitly points out why we expect a contiguous volume. That or maybe it's not necessary for it to be contiguous
- denotes the "Bayesian prior"
- is the probability of finding on under a stochastic optimizer like SGD trained to 100% accuracy on .
- is the probability of finding on upon randomly sampling parameters from i.i.d. Gaussians to get 100% accuracy on .
- This is what Mingard et al. call "Bayesian inference"
- if is consistent with and otherwise I.e.: Hessians with small eigenvalues.
Flat minima seem to be linked with generalization:
- Hochreiter and Schmidhuber, 1997a; Keskar et al., 2016; Jastrzebski et al., 2018; Wu et al., 2017; Zhang et al., 2018; Wei and Schwab, 2019; Dinh et al., 2017.
SGD
Problems:
- Suitable reparametrizations can change flatness without changing computation.
Initialization Favors "simple" functions
- Levin et al. tell us that many real-world maps satisfy , where is a computable approximation of the true Kolmogorov complexity .
- Empirically, maps of the form satisfy a similar upper bound using a computable complexity measure (CSR).
- This is an upper bound, not more than that!
- The initialization acts as our prior in Bayesian inference.
SGD Performs Hidden Regularization
- **Bayesian inference preserves the "simplicity" of the prior.
- SGD performs a kind of "Bayesian inference"
- You can approximate with Gaussian Processes.
- Mingard's main result is that appears to hold for many datasets (MNIST, Fashion-MNIST, IMDb movie review, ionosphere), architectures (Fully connected, Convolutional, LSTM), optimizers (SGD, Adam, etc.), training schemes (including overtraining) and optimizer hyperparameters (e.g. batch size, learning rate).
- Optimizer hyperparameters matter much less than
Singular Learning theory
Glossary
- is the true function
- is some implemented function
- is our neural network
- is a dataset of pairs
- are the training & test sets, respectively.
Learnability
- PAC in original formulation: simpler functions are easier to learn (polynomial time)
Usually, the true relation is probabilistic. In this case, we're not interested in a deterministic mapping from elements of to elements , but a probability distribution, , which relates random variables and (where and are the associated sample spaces).
We don't have direct access to , but we do have access to a dataset of samples, , which is itself a random variable. We specify some loss function, , , which maps a prediction, , and true value, , to a "loss". Assuming,
Usually, the true relation is probabilistic. In this case, we're not interested in a deterministic relation , but a probabilistic ground truth, given by some distribution, .
Formally, we're trying to find the weights, , that minimize the expected risk ("generalization error") for some choice of loss function, ,
We don't have direct access to the probability distribution, , generating our data, so we approximate the expectation with an empirical average over a dataset to get the empirical risk or "test loss". 2 More accurately, we optimize on a training set, , but report performance on a test set, , to avoid sampling bias and overfitting, where and . 3
Footnotes
-
Equivalently, we could separately model the likelihood and prior , then multiply to get the joint distribution. P.S. I prefer using and to mean the model and truth, respectively, but I'm keeping to the notation of Watanabe in Algebraic Geometry and Singular Learning Theory. ↩
-
Traditionally, statistical learning theory drops the explicit dependence on , and instead looks at model selection at the level of , . As we're interested in neural networks, we'll find it useful to fix a particular functional form of our model and look at selection of suitable parameters in . Later, we'll see that the understanding the mapping is at the heart of understanding why deep neural networks work as well as they do. ↩ ↩2
-
From Guedj [1]: "The past few decades have thus seen an increasing gap between the Bayesian statistical literature, and the machine learning community embracing the Bayesian paradigm – for which the Bayesian probabilistic model was too much of a constraint and had to be toned down in its influence over the learning mechanism. This movement gave rise to a series of works which laid down the extensions of Bayesian learning[.]" ↩ ↩2 ↩3 ↩4
-
. TODO: Something something Safe Bayes ↩