MNIST-CIFAR Dominoes
Here are some dominoes based on [1]. The idea behind this dataset is that there are two "patterns" in the data: the MNIST image and the CIFAR image.

Notice that some of the dominoes have only one "pattern" present. By tracking training/test loss on these one-sided dominoes, we can tease apart how quickly the model learns the two different patterns.
We'd like to compare these pattern-learning curves to the curves predicted by the toy model of [2]. In particular, we'd like to compare predictions to the empirical curves as we change the relevant macroscopic parameters (e.g., prevalence, reliability, and simplicity1).
Which means running sweeps over these macroscopic parameters.
Prevalence
What happens as we change the relative incidence of MNIST vs CIFAR images in the dataset? We can accomplish this by varying the frequency of one-sided MNIST dominoes vs. one-sided CIFAR dominoes.
We control two parameters:
- , the probability of a domino containing an MNIST image (either one-sided or two-sided),
- , the probability of a domino containing a CIFAR image (either one-sided or two-sided), and
Two parameters are fixed by our datasets:
- , the number of samples in the MNIST dataset.
- , the number of samples in the CIFAR dataset.
Given these parameters, we have to determine:
- , the fraction of the MNIST dataset that we reject,
- , the fraction of the MNIST dataset that ends up in one-sided dominoes,
- , the fraction of the MNIST dataset that ends up in two-sided dominoes,
and, similarly, , , and for the CIFAR dataset.
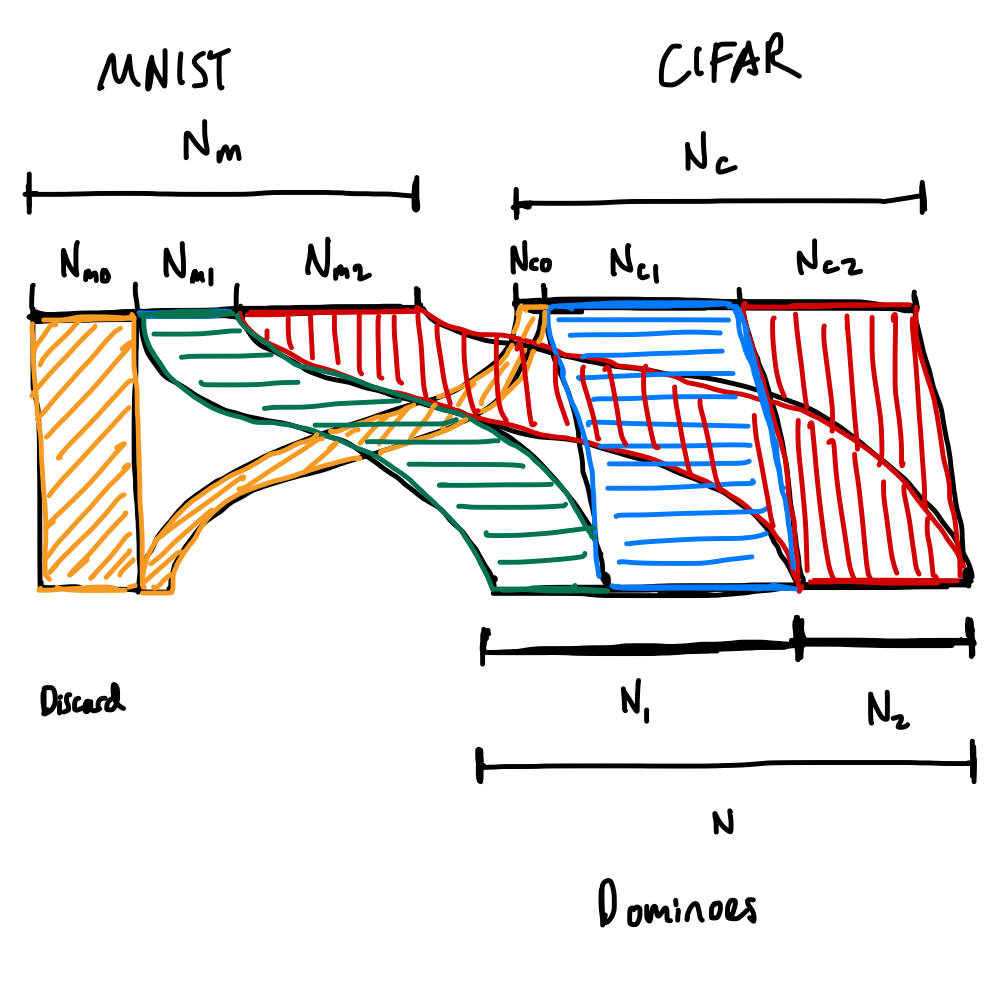 Here's the corresponding Sankey diagram (in terms of numbers of samples rather than probabilities, but it's totally equivalent).
Here's the corresponding Sankey diagram (in terms of numbers of samples rather than probabilities, but it's totally equivalent).
Six unknowns means we need six constraints.
We get the first two from the requirement that probabilities are normalized,
and the another from the double dominoes requiring the sample number of samples from both datasets,
Out of convenience, we'll introduce an additional variable, which we immediately constrain,
the number of samples in the resulting dominoes dataset.
We get the last three constraints from our choices of , , and :
In matrix format,
where .
So unfortunately, this yields trivial answers where and all other values are 0. The solution seems to be to just allow there to be empty dominoes.
Reliability
We can vary the reliability by inserting "wrong" dominoes. I.e.: with some probability make either of the two sides display the incorrect class for the label.
Simplicity
One of the downsides of this task is that we don't have much control over the simplicity of the feature. MNIST is simpler than CIFAR, sure, but how much? How might we control this?
Footnotes
-
Axes conceived by Ekdeep Singh Lubana. ↩