Scaling Laws of Path dependence
NOTE: Work in Progress
How much do the models we train depend on the path they follow through weight space?
Should we expect to always get the same models for a given choice of hyperparameters and dataset? Or do the outcomes depend highly on quirks of the training process, such as the weight initialization and batch schedule?
If models are highly path-dependent, it could make alignment harder: we'd have to keep a closer eye on our models during training for chance forays into deception. Or it could make alignment easier: if alignment is unlikely by default, then increasing the variance in outcomes increases our odds of success.
Vivek Hebbar and Evan Hubinger have already explored the implications of path-dependence for alignment here. In this post, I'd like to formalize "path-dependence" in the language of dynamical systems, and share the results of experiments inspired by this framing.
From these experiments, we find novel scaling laws relating choices of hyperparameters like model size, learning rate, and momentum to the trajectories of these models during training. We find functional forms that provide a good empirical fit to these trajectories across a wide range of hyperparameter choices, datasets, and architectures.
Finally, we study a set of toy models that match the observed scaling laws, which gives us insight into the possible mechanistic origins of these trends, and a direction towards building a theory of the dynamics of training.
Formalizing Path-dependence
Hebbar and Hubinger define path-dependence "as the sensitivity of a model's behavior to the details of the training process and training dynamics." Let's make that definition more precise. To start, let us formalize the learning process as a dynamical system over weight space.
In the context of machine learning, our goal is (usually) to model some "true" function 1. To do this, we construct a neural network, , which induces a model of upon fixing a choice of weights, . For convenience, we'll denote the resulting model with a subscript, i.e., .2
To find the weights, , such that is as "close" as possible to , we specify a loss function , which maps a choice of parameters and a set of training examples, , to a scalar "loss"3:
For a fixed choice of dataset, we denote the empirical loss, . Analogously, we can define a test loss, over a corresponding test set, and batch loss, , for a batch .
Next, we choose an optimizer, , which iteratively updates the weights (according to some variant of SGD),
The optimizer depends on some hyperparameters, , and learning schedule of batches, . Note: this learning schedule covers all epochs. In other words, if an epoch consists of batches, then . Within any given epoch, the batches are disjoint, but across epochs, repetition is allowed (though typically no batch will be repeated sample for sample).
If we take the learning schedule and hyperparameters as constant, we obtain a discrete-time dynamical system over parameter space, which we denote .
Two Kinds of Path Dependence
Given this dynamical system, over weight space, let us contrast two kinds of path dependence:
- Global path dependence. Given some distribution over starting weights, , hyperparameters, , or batches, , what is the resulting distribution over final weights, ?
- Local path dependence. For some choice of initial weights, , hyperparameters, , or batches, , and a small perturbation (of size ) to one of these values, how "different" does the perturbed model end up being from the baseline unperturbed model? In the limit of infinitesimal perturbations, this reduces to computing derivatives of the kind , , and .
Though we ultimately want to form global statements of path dependence, the distributions involved are generally intractable (which require us to resort to empirical approximations). In the local view, we rarely care about specific perturbations, so we end up studying the relation between a similarly intractable distribution over perturbations and . Still, this is much easier to explore empirically because of its smaller support.
Continuous vs. Discrete Hyperparameters
Below, is a table of the various hyperparameters we encounter in our model, weight initializer, optimizer, and dataloader. Here, we're taking "hyperparameter" in the broadest sense to incorporate even the dataset and choice of model architecture.
To study local perturbations, we're interested in those hyperparameters that we can vary continuously. E.g.: we can gradually increase the magnitude of the perturbation applied to our baseline model, as well as the momenta, regularization coefficients, and learning rates of the optimizer, but we can't smoothly vary the number of layers in our model or the type of optimizer we're using.
From weights to functions
The problem with studying dynamics over is that we don't actually care about . Instead, we care about the evolution in function space, , which results from the mapping .
We care about this evolution because the mapping to function space is non-injective; the internal symmetries of ensure that different choices of can map to the same function .[1] As a result, distance in can be misleading as to the similarity of the resulting function.
The difficulty with function space is that it is infinite-dimensional, so studying it is that much more intractable than studying weight space. In practice, then, we have to estimate where we are in function space over a finite number of samples of input-output pairs, for which we typically use the training and test sets.
However, even though we have full knowledge of , we can't resolve exactly where we are in from any finite set of samples. At best, we can resolve the level set in with a certain empirical performance (like training/test loss). This means our sampling procedure acts as a second kind of non-injective map from .
A note on optimizer state: If we want to be exhaustive, let us recall that optimizers might have some internal state, . E.g., for Adam, , a running average of the first moment and second moment of the gradients, respectively. Then, the dynamical system over is more appropriately a dynamical system over the joint space . Completing this extension will have to wait for another day; we'll ignore it for now for the sake of simplicity and because, in any case, , tends to be a deterministic function of and .
Experiments
In section XX, we defined path dependence as about understanding the relation between and . As mentioned, there are two major challenges:
- In general, we have to estimate these distributions empirically, and training neural networks is already computationally expensive, so we're restricted to studying smaller networks and datasets.
- The mapping is non-straightforward because of the symmetries of .
To make it easier for ourselves, let us restrict our attention to the narrower case of studying local path-dependence.
a (small) perturbation, , to one of . E.g., we'll study probability densities of the kind . For discrete variables (like the number of layers, network width, and batch schedule), there's a minimum size we can make ,
Within dynamical systems theory, there are two main ways to view dynamical systems:
- The trajectory view studies the evolution of points like and .
- The probability view studies the evolution of densities like and .
Both have something to tell us about path dependence:
- In the trajectory view, sensitivity of outcomes becomes a question of calculating Lyapunov exponents, the rate at which nearby trajectories diverge/converge.
- In the probability view, sensitivity of outcomes becomes a question of measuring autocorrelations, and .
Tracking Trajectories
The experimental set-up involves taking some baseline model, , then applying a Gaussian perturbation to the initial weights with norm , to obtain a set of perturbed models . We train these models on MNIST (using identical batch schedules for each model).
Over the course of training, we track how these models diverge via several metrics (see next subsection). For each of these, we study how the rate of divergence varies for different choices of hyperparameters: momentum , weight decay , learning rate , hidden layer width (for one-hidden-layer models), and number of hidden layers. Moving on from vanilla SGD, we compare adaptive variants like Adam and RMSProp.
TODO: Non-FC models. Actually calculate the rate of divergence (for the short exponential period at the start). Perform these experiments for several different batch schedules. Perturbations in batch schedule. Other optimizers besides vanilla SGD.
Measuring distance
- : the -norm between the weight vectors of each perturbed model and the baseline model. We'll ignore the throughout and restrict to the case . This is the most straightforward notion of distance, but it's flawed in that it can be a weak proxy for distance in because of the internal symmetries of the model.
- : the relative -norm between weight vectors of each perturbed model.
- : the training/test losses
- : the training/test loss relative (difference) to the baseline model
- , : the training/test set classification accuracy and relative classification accuracy.
- and : same as above, but we take the predictions of the baseline model as the ground truth (rather than the actual labels in the test set).
A few more metrics to include:
- : the l2 norm after adjusting for permutation differences (as described in Ainsworth et al.)
- . The loss integrated over the linear interpolation between two models' weights after correcting for permutations (as described in Ainsworth et al.)
Tracking Densities
TODO
Results
One-hidden-layer Models
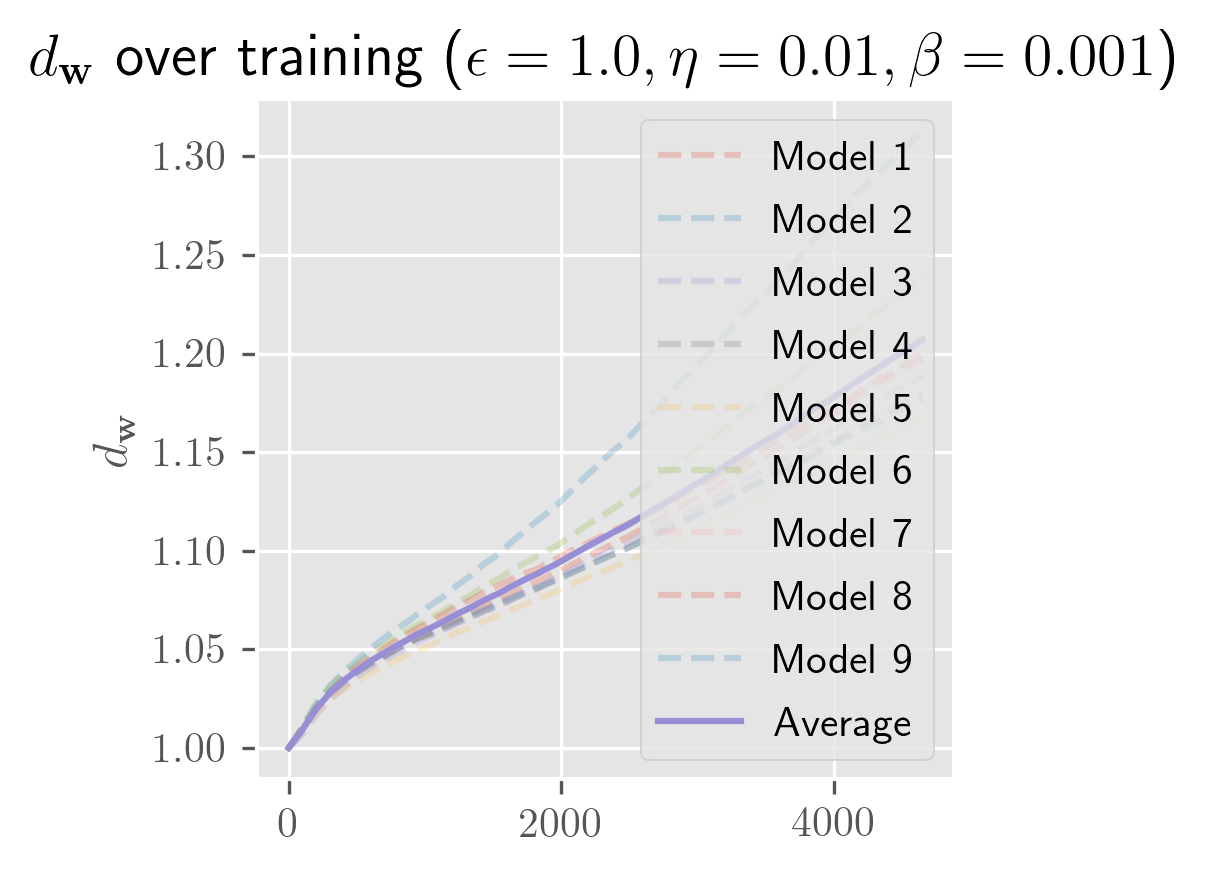
What's remarkable about one-hidden-layer models is how little the model depends on weight initialization: almost all of the variance seems to be explained by the batch schedule. Even for initial perturbations of size 1, the models appear to become almost entirely equivalent in function space across the entire training process. In the figure below, you can see that the differences in are imperceptible (both for a fixed and across averages over different ).
TODO: I haven't checked . I'm assuming this is >1 for (which is why I find this surprising), but I might be confused about PyTorch's default weight initialization scheme. So take this all with some caution.
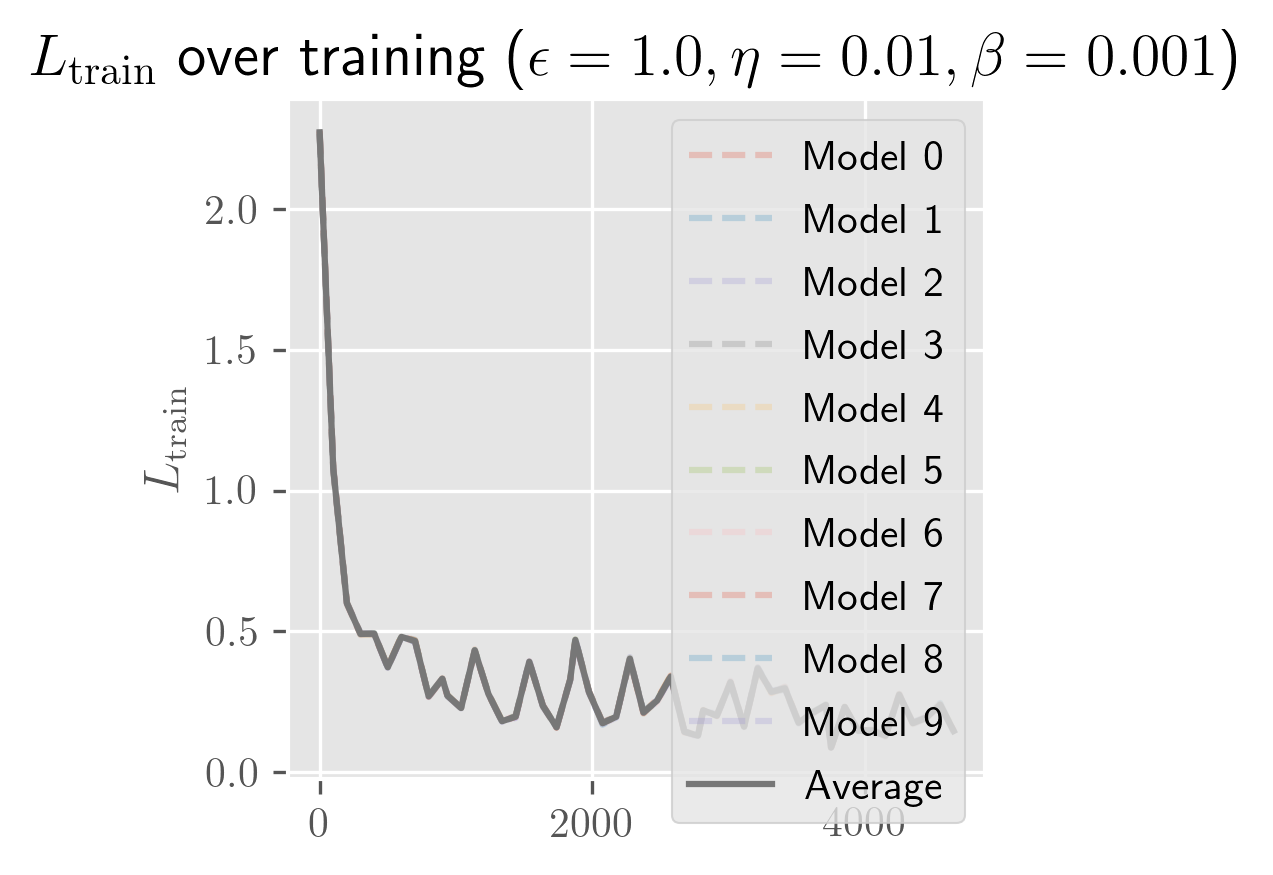
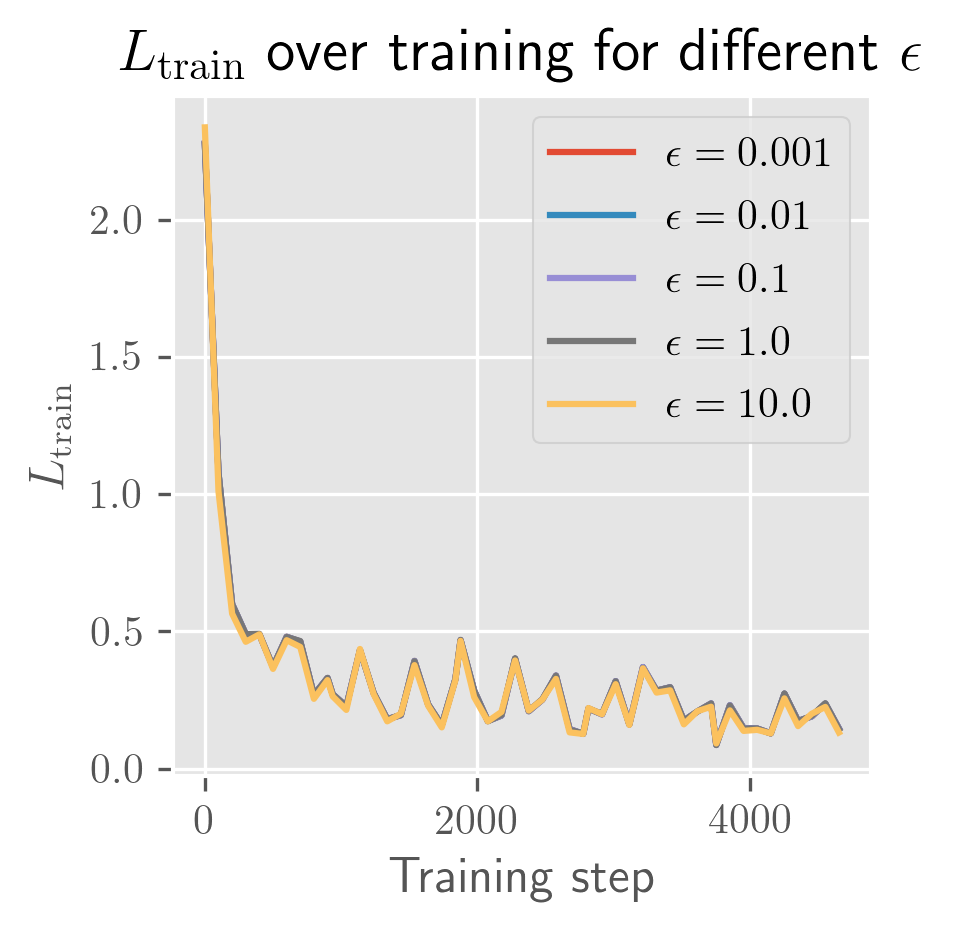
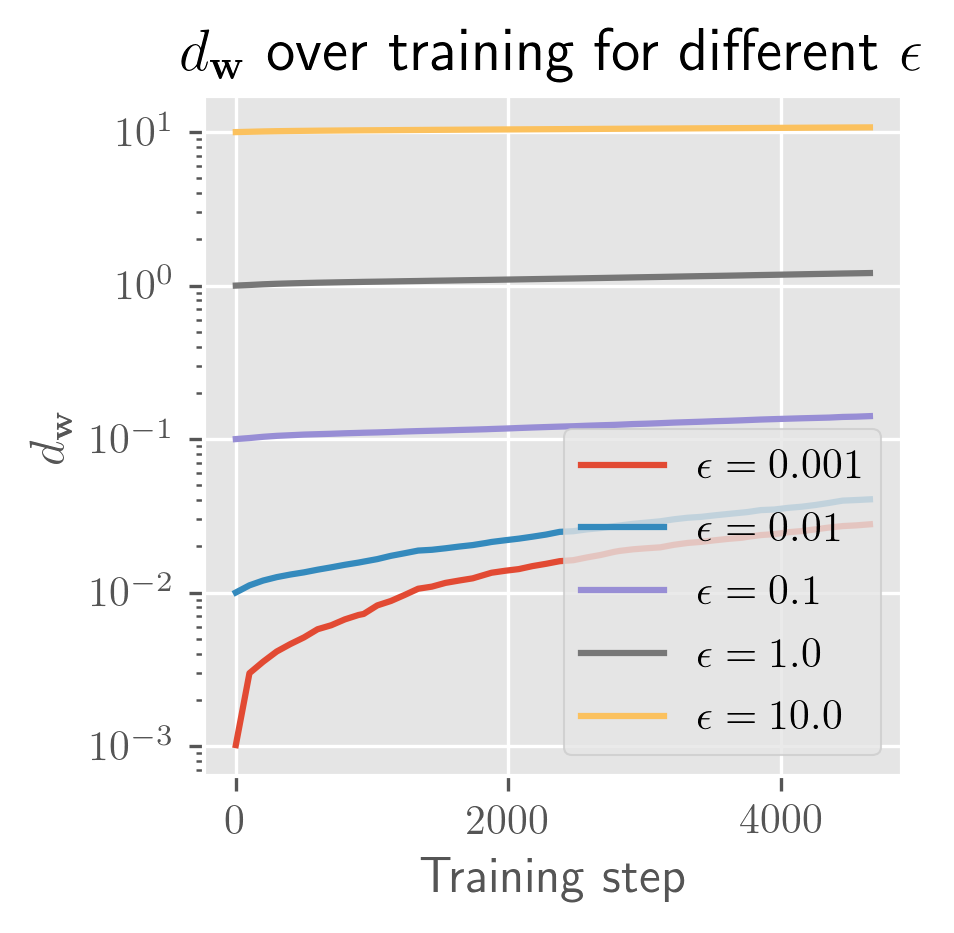
The rate of growth for has a very short exponential period (shorter than a single epoch), followed by a long linear period (up to 25 epochs, long past when the error has stabilized). In some cases, you'll see a slight bend upwards or downwards. I need more time to test over more perturbations (right now it's 10 perturbed models) to clean this up. Maybe these trends change over longer periods, and with a bit more time I'll test longer training runs and over more perturbations.
Hyperparameters
- Momentum: () The curves look slightly more curved upwards/exponential but maybe that's confirmation bias (I expect momentum to make divergence more exponential back when I expected exponential divergence). Small amounts of momentum appear to increase convergence (relative to other models equivalent up to momentum), while large amounts increase divergence (towards . For very small amounts, the effect appears to be negligible. Prediction: the curves curve down because in flat basins, momentum slows you down.
- Learning rate: Same for . (Not too surprising) TODO: Compare directly between different learning rates. Can we see back in the slope of divergence? Prediction: This should not make much of a difference. I expect that correcting for the learning rate should give nearly identical separation slopes.
- Weight Decay: TODO for . Prediction: will shrink (because will shrink). The normalized will curve downwards because we break the ReLU-scaling symmetry which means the volume of our basins will shrink
- Width: TODO. Both this and depth require care. With different sizes of , we can't naively compare norms. Is it enough to divide by ? Prediction: I expect the slope of divergence to increase linearly with the width of a one-layer network (from modeling each connection as separating of its own linear accord).
- Depth: TODO. Prediction: I expect the shape of for each individual layer to become more and more exponential with depth (because the change will be the product of layers that diverge linearly independently). I expect this to dominate the overall divergence of the networks.
- Architecture: Prediction: I expect convolutional architectures to decrease the rate of separation (after correcting for the number of parameters).
- Optimizer:
- Prediction: I expect adaptive techniques to make the rate of divergence exponential.
Datasets
- Computer Vision
- MNIST
- Fashion-MNIST
- Imagenet: Prediction: I expect Imagenet to lead to the same observations as MNIST (after correcting for model parameter count).
- Natural Language
- IMDb movie review database
Why Linear?
I'm not sure. My hunch going in was that I'd see either exponential divergence (indicating chaos) or square root divergence (i.e., Brownian noise). Linear surprises me, and I don't yet know what to make of it.
Maybe all of this is just a fact about one-hidden-layer networks. If each hidden layer evolves independently linearly, maybe this combines additively into something Brownian. Or maybe it's multiplicative (so exponential).
Deep Models
TODO
Appendix
Weight Initialization
For ReLU-based networks, we use a modified version of Kaiming (normal) initialization, which is based on the intuition of Kaiming initialization as sampling weights from a hyperspherical shell of vanishing thickness.
Kaiming initialization is sampling from a hyperspherical shell
Consider a matrix, , representing the weights of a particular layer with shape . is also called the fan-in of the layer, and the fan-out. For ease of presentation, we'll ignore the bias, though the following reasoning applies equally well to the bias.
We're interested in the vectorized form of this matrix, , where .
In Kaiming initialization, we sample the components, , of this vector, i.i.d. from a normal distribution with mean 0 and variance (where ).
Geometrically, this is equivalent to sampling from a hyperspherical shell, with radius and (fuzzy) thickness, .
This follows from some straightforward algebra (dropping the superscript for simplicity):
and
So the thickness as a fraction of the radius is
where the last equality follows from the choice of for Kaiming initialization.
This means that for suitably wide networks (), the thickness of this shell goes to .
Taking the thickness to 0
This suggests an alternative initialization strategy: sample directly from the boundary of a hypersphere with radius , i.e., modify the shell thickness to be .
This can easily be done by sampling each component from a normal distribution with mean 0 and variance and then normalizing the resulting vector to have length (this is known as the Muller method).
Perturbing Weight initialization
Naïvely, if we're interested in a perturbation analysis of the choice of weight initialization, we prepare some baseline initialization, , and then apply i.i.d. Gaussian noise, , to each of its elements, .
The problem with this is that the perturbed weights are no longer sampled from the same distribution as the baseline weights. In terms of the geometric picture from the previous section, we're increasing the thickness of the hyperspherical shell in the vicinity of the baseline weights.
There is nothing wrong with this per se, but it introduces a possible confounder (the thickness).
The modification we made to Kaiming initialization was to sample directly from the boundary of a hypersphere, rather than from a hyperspherical shell. This is a more natural choice when conducting a perturbation analysis, because it makes it easier to ensure that the perturbed weights are sampled from the same distribution as the baseline weights.
Geometrically, the intersection of a hypersphere of radius with a hypersphere of radius that is centered at some point on the boundary of the first hypersphere, is a lower-dimensional hypersphere of a modified radius . If we sample uniformly from this lower-dimensional hypersphere, then the resulting points will follow the same distribution over the original hypersphere.
This suggests a procedure to sample from the intersection of the weight initialization hypersphere and the perturbation hypersphere.
First, we sample from a hypersphere of dimension and radius (using the same technique we used to sample the baseline weights). From a bit of trigonometry, see figure below, we know that the radius of this hypersphere will be , where .
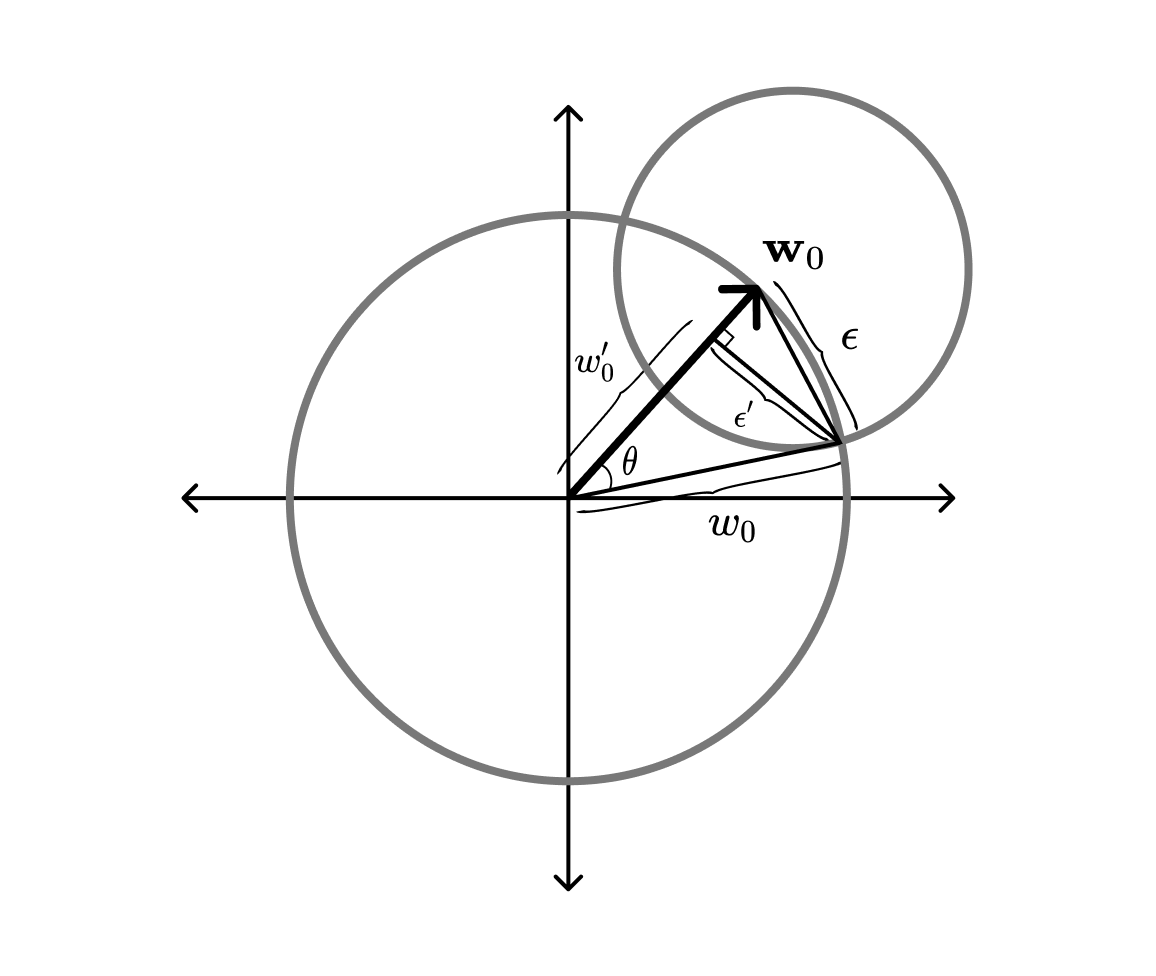
Next, we rotate the vector so it is orthogonal to the baseline vector . This is done with a Householder reflection, , that maps the current normal vector onto :
where
and is the unit vector in the direction of the baseline weights.
Implementation note: For the sake of tractability, we directly apply the reflection via:
Finally, we translate the rotated intersection sphere along the baseline vector, so that its boundary goes through the intersection of the two hyperspheres. From the figure above, we find that the translation has the magnitude .
By the uniform sampling of the intersection sphere and the uniform sampling of the baseline vector, we know that the resulting perturbed vector will have the same distribution as the baseline vector, when restricted to the intersection sphere.
Dynamical Systems
Formally, a dynamical system is a tuple , where is the "time domain" (some monoid), is the phase space over which the evolution takes place (some manifold), and is the evolution function, a map,
that satisfies, ,
Informally, we're usually interested in one of two perspectives:
- Trajectories of individual points in , or
- Evolution of probability densities over .
The former is described in terms of differential equations (for continuous systems) or difference equations (for discrete systems), i.e.,
or
The latter is described in terms of a transfer operator:
Both treatments have their advantages: the particle view admits easier empirical analysis (we just simulate a trajectory), while the latter
In terms of the former, path-sensitivity becomes the question of chaos: do nearby
Varying the Depth
For a fair comparison across network depths, we want to keep the total number of parameters constant as we increase depth.
Given hidden layers with biases that each have width, , an input dimensionality of , and an output dimensionality of , the total number of parameters is
Lyapunov spectrum
The Lyapunov exponent quantifies the rate of separation of infinitesimally close trajectories:
If the exponent is positive, then nearby trajectories will diverge, and the dynamics are chaotic. If the exponent is negative, then nearby trajectories will converge
For a -dimensional system, there are Lyapunov exponents. We often focus exclusively on the maximal Lyapunov exponent because it dominates the overall rate of separation between two neighboring trajectories. However, the full spectrum contains valuable additional information like the rate of entropy production, the fractal dimension, the Hausdorff dimension, and the Lyapunov dimension.
The first major limitation is that the full Lyapunov spectrum is intractable for large . The other major limitation is that the Lyapunov spectrum requires a suitable norm. We can use the l2 norm in , but as we already saws what we really care about is measuring distance in with some metric .
One option would be to repurpose the loss function :
Here, we treat as the truth, and use the empirical risk as our distance metric. We could define an analogous distance over either the train or test set. As long as is a suitable metric (or easily converted into a metric through, e.g., symmetrization), will be too.
This suffers a major downside that two functions will be seen as identical as long as they have the same performance on the dataset in question. They can have totally different performance on unseen examples. Devising suitable distance metrics for neural networks requires more work.

Autocorrelations
The autocorrelation of a random process is the correlation between two values of that process at different times,
For stationary processes (where is independent of ), this becomes a function of one variable, ,
In the case of training, the dynamics aren't stationary: learning rate schedules and the the "descent" of gradient descent ensures that these correlations will depend on our choice of starting time. However, we're not typically interested in correlations between later time steps. We care about autocorrelations relative to the starting point .
In practice, the probabilistic and point-wise views are intimately connected: the relevant autocorrelation timescales can often be directly related to the maximal Lyapunov component. These two formulas are only a small sample of the available tooling.
is the space of -integrable functions, iff
which is equipped with a metric,
So we exchange evolution over a finite-dimensional with an infinite-dimensional
Footnotes
-
For regression, , for classification, , for self-supervised tasks, we're often interested in , etc. ↩ ↩2
-
To start, we'll ignore the model hyperparameters. You can view this as either absorbing the hyperparameters into the weights, into the optimizer, or into our choice of . Later, it'll be useful to separate out hyperparameters (i.e., ). ↩
-
A quick note on notation: Often, you'll see the dataset denoted with a capital . Here, we're using a lowercase because it'll be useful to treat as an instance of a random variable . Similarly for , , and (, , and ). Even though , , and are (typically) all vectors, we'll reserve boldface for sets. TODO: Maybe just bite the bullet and bold all of them. ↩
-
It's possible to generalize this further so that , but this won't be necessary for us. ↩