Singularities against the Singularity
This is an link post, originally posted at https://www.lesswrong.com/posts/HtxLbGvD7htCybLmZ/singularities-against-the-singularity-announcing-workshop-on.
This is an link post, originally posted at https://www.lesswrong.com/posts/HtxLbGvD7htCybLmZ/singularities-against-the-singularity-announcing-workshop-on.
This is an link post, originally posted at https://www.lesswrong.com/posts/zuYRyC3zghzgXLpEW/empirical-risk-minimization-is-fundamentally-confused.
Here are some dominoes based on [1]. The idea behind this dataset is that there are two "patterns" in the data: the MNIST image and the CIFAR image.

Notice that some of the dominoes have only one "pattern" present. By tracking training/test loss on these one-sided dominoes, we can tease apart how quickly the model learns the two different patterns.
We'd like to compare these pattern-learning curves to the curves predicted by the toy model of [2]. In particular, we'd like to compare predictions to the empirical curves as we change the relevant macroscopic parameters (e.g., prevalence, reliability, and simplicity1).
Which means running sweeps over these macroscopic parameters.
What happens as we change the relative incidence of MNIST vs CIFAR images in the dataset? We can accomplish this by varying the frequency of one-sided MNIST dominoes vs. one-sided CIFAR dominoes.
We control two parameters:
Two parameters are fixed by our datasets:
Given these parameters, we have to determine:
and, similarly, , , and for the CIFAR dataset.
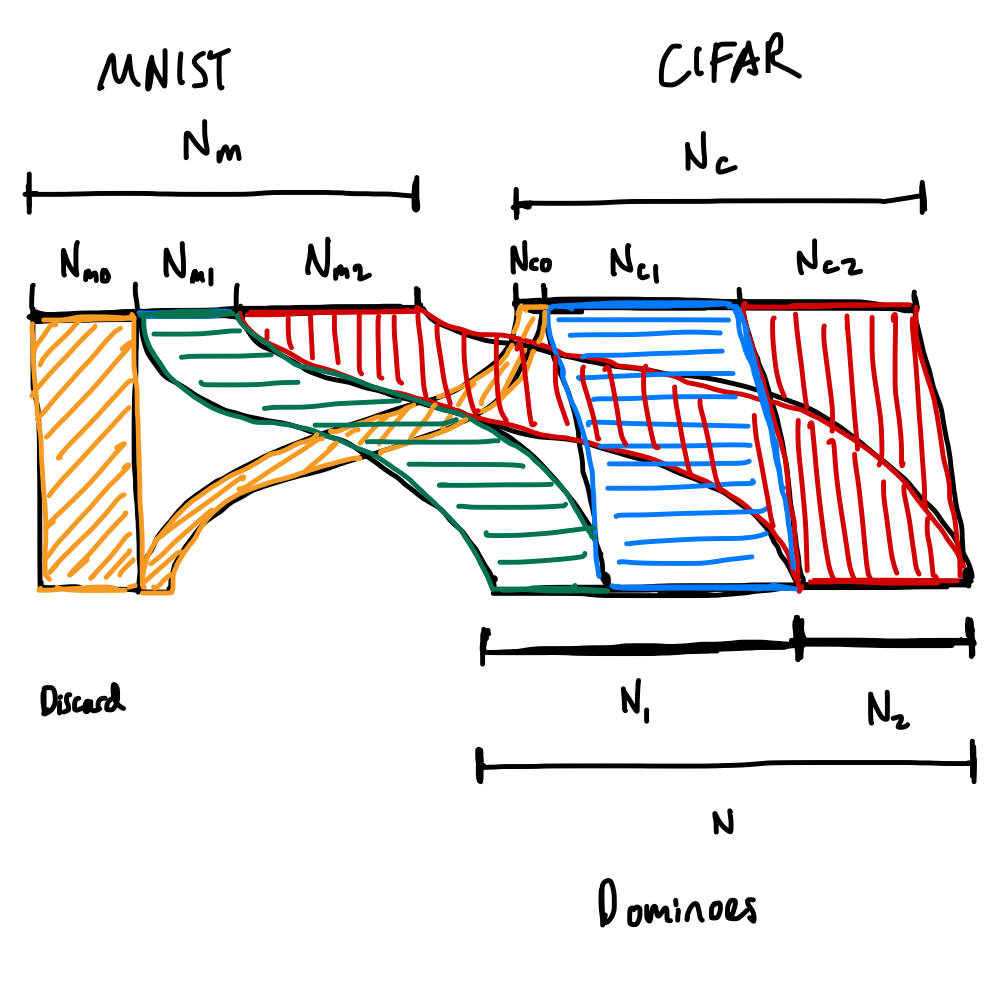 Here's the corresponding Sankey diagram (in terms of numbers of samples rather than probabilities, but it's totally equivalent).
Here's the corresponding Sankey diagram (in terms of numbers of samples rather than probabilities, but it's totally equivalent).
Six unknowns means we need six constraints.
We get the first two from the requirement that probabilities are normalized,
and the another from the double dominoes requiring the sample number of samples from both datasets,
Out of convenience, we'll introduce an additional variable, which we immediately constrain,
the number of samples in the resulting dominoes dataset.
We get the last three constraints from our choices of , , and :
In matrix format,
where .
So unfortunately, this yields trivial answers where and all other values are 0. The solution seems to be to just allow there to be empty dominoes.
We can vary the reliability by inserting "wrong" dominoes. I.e.: with some probability make either of the two sides display the incorrect class for the label.
One of the downsides of this task is that we don't have much control over the simplicity of the feature. MNIST is simpler than CIFAR, sure, but how much? How might we control this?
Axes conceived by Ekdeep Singh Lubana. ↩
Produced as part of the SERI ML Alignment Theory Scholars Program - Winter 2022 Cohort
Most results under the umbrella of "deep learning theory" are not actually deep, about learning, or even theories.
This is because classical learning theory makes the wrong assumptions, takes the wrong limits, uses the wrong metrics, and aims for the wrong objectives. Learning theorists are stuck in a rut of one-upmanship, vying for vacuous bounds that don't say anything about any systems of actual interest.
 Yudkowsky tweeting about statistical learning theorists. (Okay, not really.)
Yudkowsky tweeting about statistical learning theorists. (Okay, not really.)
In particular, I'll argue throughout this sequence that:
That said, there are new approaches that I'm more optimistic about. In particular, I think that singular learning theory (SLT) is the most likely path to lead to a "theory of deep learning" because it (1) has stronger theoretical foundations, (2) engages with the structure of individual models, and (3) gives us a principled way to bridge between this microscopic structure and the macroscopic properties of the model class1. I expect the field of mechanistic interpretability and the eventual formalism of phase transitions and "sharp left turns" to be grounded in the language of SLT.
A mathematical theory of learning and intelligence could form a valuable tool in the alignment arsenal, that helps us:
That's not to say that the right theory of learning is risk-free:
All that said, I think the benefits currently outweigh the risks, especially if we put the right infosec policy in place when if learning theory starts showing signs of any practical utility. It's fortunate, then, that we haven't seen those signs yet.
My aims are:
There's also the question of integrity: if I am to criticize an entire field of people smarter than I am, I had better present a strong argument and ample evidence.
Throughout the rest of this sequence, I'll be drawing on notes I compiled from lecture notes by Telgarsky, Moitra, Grosse, Mossel, Ge, and Arora, books by Roberts et al. and Hastie et al., a festschrift of Chervonenkis, and a litany of articles.3
The sequence follows the three-fold division of approximation, generalization, and optimization preferred by the learning theorists. There's an additional preface on why empirical risk minimization is flawed (up next) and an epilogue on why singular learning theory seems different.
This sequence was inspired by my worry that I had focused too singularly on singular learning theory. I went on a journey through the broader sea of "learning theory" hopeful that I would find other signs of useful theory. My search came up mostly empty, which is why I decided to write >10,000 words on the subject. ↩
Though, granted, string theory keeps on popping up in other branches like condensed matter theory, where it can go on to motivate practical results in material science (and singular learning theory, for that matter). ↩
I haven't gone through all of these sources in equal detail, but the content I cover is representative of what you'll learn in a typical course on deep learning theory. ↩
This is an link post, originally posted at https://www.lesswrong.com/posts/BDTfddkttFXHqGnEi/the-shallow-reality-of-deep-learning-theory.